Research :
안녕하세요. 제 Git Page의 첫 게시물로 SSD(Single shot Multi-box Detector)에 대한 포스팅을 해보려 합니다.
1년 전(2019년) SSD에 대해 궁금한 것이 너무 많았지만 상세한 자료를 찾는게 쉽지 않았습니다.
특히 한국어로 번역된 자료는 매우 드물었기에 직접 공부해서 한국어 포스트를 작성하기로 마음 먹었고, 지금에서야 포스트를 쓸 수 있게 되었습니다.
이 글에서는 SSD 논문과 해외 여러 포스트, 저서들을 토대로 아주 상세한 내용을 다뤄보고 이를 직접 구현한 코드를 해설해보겠습니다.
인공지능에 입문하는 분, 수학을 잘 모르시는 분도 읽기 쉽게 준비했습니다.
서론 I : 단계별 사물 인식
시작하기에 앞서, 이미지 인식은 목적에 따라 세 단계로 나눌 수 있습니다.
영어로는 세 단계가 확실히 구분되지만, 한국어로는 대부분 ‘인식’으로 번역할 수 있기 때문에 자료 수집에 혼란이 되었던 부분입니다.
그러므로 목적에 따라 키워드를 구분해 사용하는 것이 좋습니다.
- 하나의 이미지 전체가 어떤 사물을 표현하는 것인지 분류하는 ‘Classification’
- 하나의 이미지에 어떤 사물들이 표현되어 있는지 식별하는 ‘Recognition’
- 하나의 이미지에 사물들이 어떤 형태를 가지고 있는지 분리하는 ‘Segmentation’
이 중 ‘Classification’과 ‘Recognition’을 묶어 ‘Detection’이라는 키워드를 사용할 수 있습니다.
쉬운 이해를 위해 그림으로 표현하면 이렇습니다.
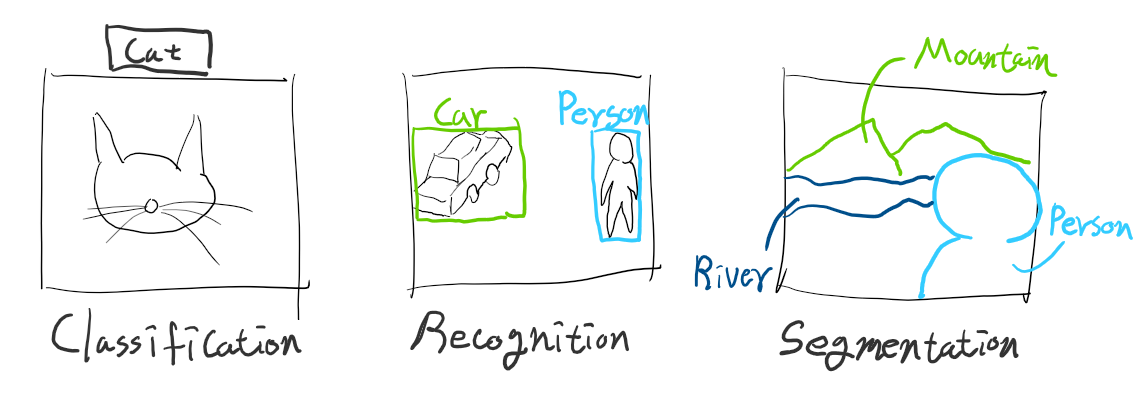
Classification은 이미지를 전체적으로 인식하고, Recognition은 이미지에 표현된 여러 개체의 위치와 크기를 인식하며, Segmentation은 이미지에 표현된 개체들이 어떤 형태인지 인식합니다.
즉, SSD는 사물을 박스로 추측하기 때문에 한 이미지에 표현된 여러 사물들을 식별해내기 위한 Recognition 모델입니다.
Computer Vision에서 주로 사용되는 CNN은 Sliding Window 탐색 기법으로 (인공지능의 입장에서)원하는 픽셀에 영향력을 강하게 주어 이미지를 분류하는 기준을 정하도록 학습하는 원리를 갖고 있습니다.
서론 II : Classification과 Recognition 구조 차이
Classification 신경망(이하 분류망)과 Recognition 신경망(이하 식별망)의 차이는 모두가 짐작할 수 있듯이 출력에 있습니다. 분류망은 원하는 값을 즉시 출력하도록 설계되어 있습니다. 예를 들어 숫자 필기 이미지를 인식한다고 했을 때 이미지를 분류망에 입력해 0~9를 표현하는 10개의 출력을 하도록 되어 있습니다.
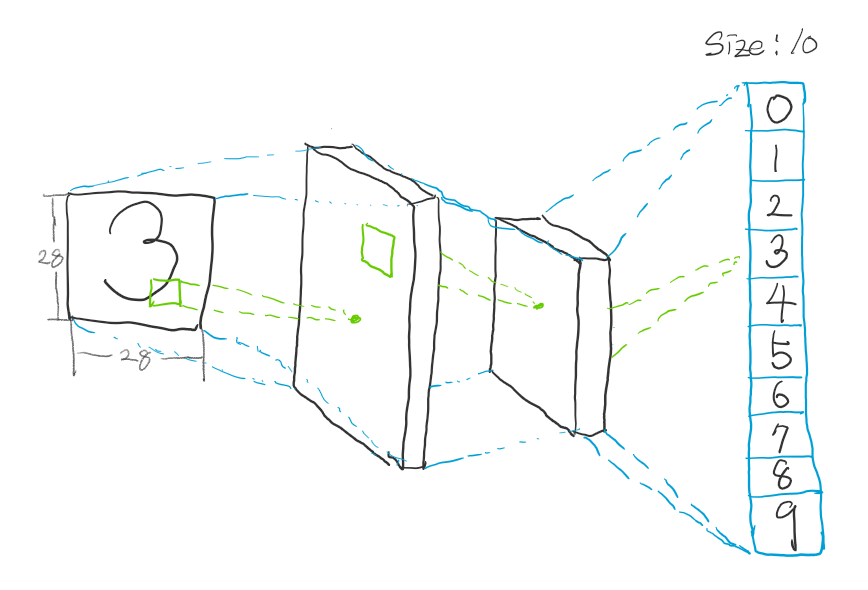
하지만 식별망은 어떨까요? 만약 분류망처럼 원하는 출력을 그대로 뽑아낸다고 생각해봅시다. 앞서 언급한 숫자 필기 인식 모델에 이어서, 1개의 이미지에 다수의 필기가 표현된다고 가정합니다.
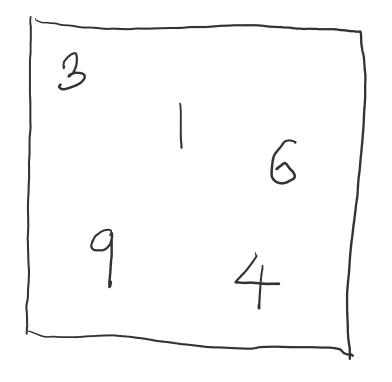
그렇다면, 식별망의 출력은 각 개체 당 식별 코드(Identifier)와 좌표(Coordinates)로 이루어져 있는 여러 개의 필드로 구성되어있을 것입니다.
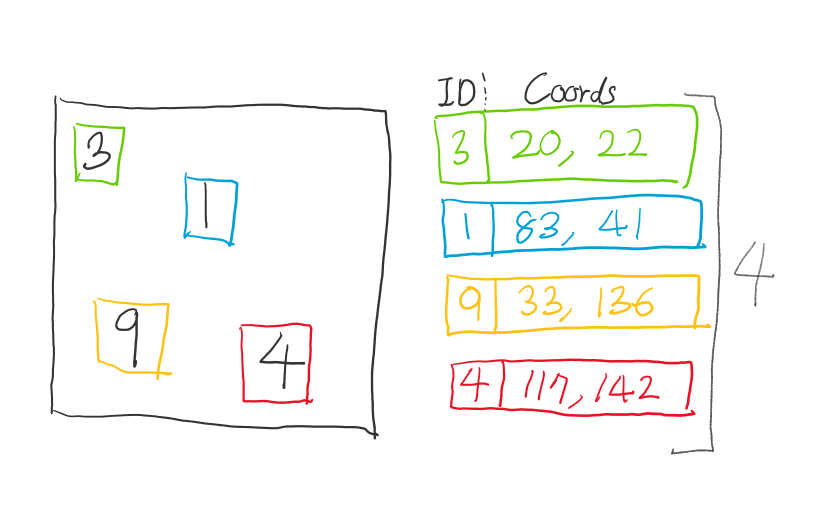
하지만 이미지 마다 표현하는 개체의 수는 다를 것입니다. 요컨대, 1개의 필드 크기는 고정되어 있지만 필드의 개수가 고정되어 있지 않다는 겁니다. 그러므로 출력의 크기가 항상 고정되어 있지 않다고 할 수 있습니다.
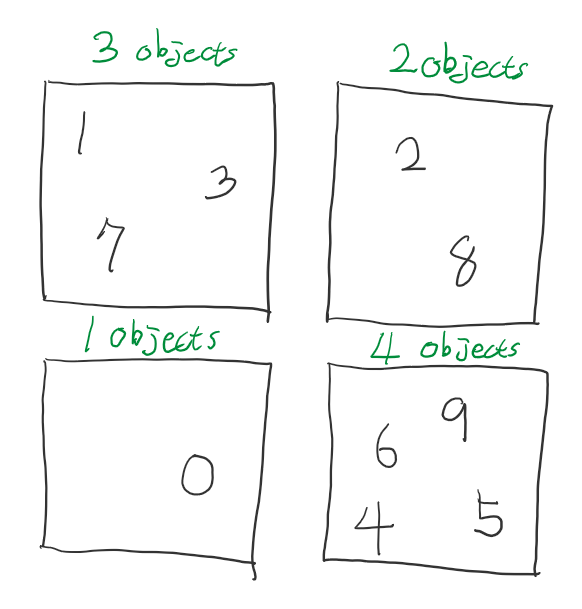
‘그러면 신경망의 출력을 유동적으로 조절하면 되지 않나?’ 라는 의문을 가질 수 있겠지만, 인공신경망은 자료 구조에서 표현하는 그래프 구조를 갖고 있습니다. 즉, 수 많은 노드들이 있고 모든 노드들이 연결되어 연산합니다. 그렇기에 신경망의 출력이 조절되면 노드들의 연결이 변경된다는 의미이기도 하기 때문에 학습을 시도할 때마다 신경망이 연산 능력을 잃게되는 현상이 발생합니다.
SSD와 YOLO 등 Recognition을 다룬 논문에서는 이 문제를 해결하기 위해 마치 사용자 입력을 위한 배열을 선언하듯 필드 공간을 넉넉하게 만드는 방법을 사용했습니다. 이 방법에 대해서는 본론에서 소개하겠습니다.
또, SSD는 여기에 좋은 아이디어를 추가해 다양한 크기의 개체를 빠르면서도 정확하게 예측해내도록 설계했습니다.
본론
신경망 구조
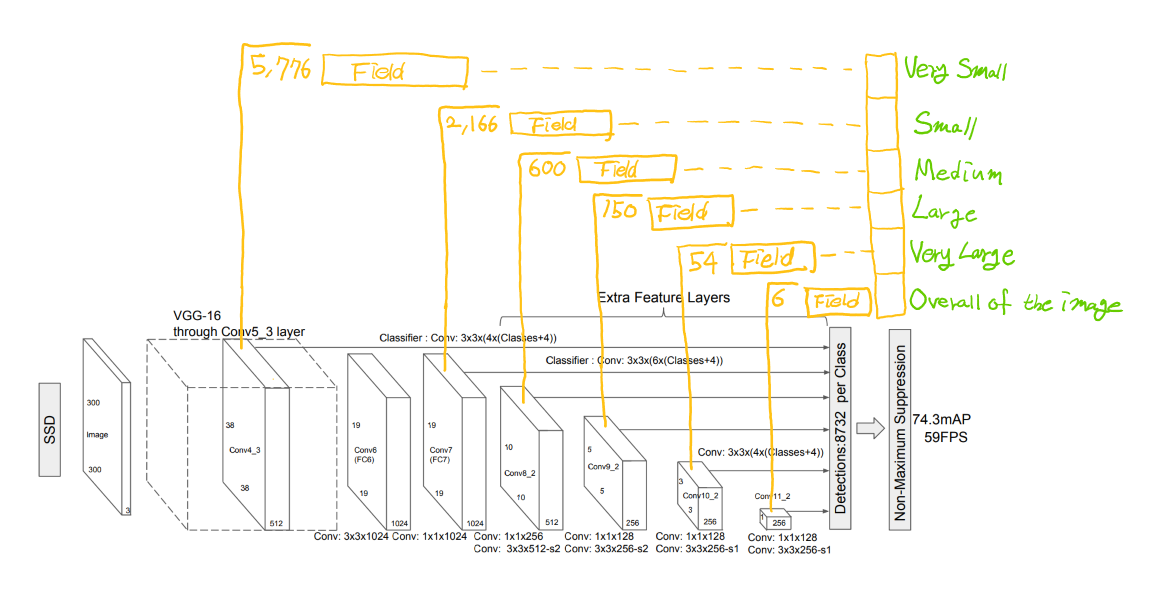
SSD의 구조는 크게 2개의 신경망이 연결되어있는 구조입니다. 입력을 받아 이미지의 수 많은 특징을 추출해내는 신경망을 ‘Backbone Network’, 이 특징들을 받아 Box를 예측해내는 신경망을 ‘Extra Network’ 또는 ‘Feature Extractor’, ‘Bounding Box Network(이하 BBox Network)’ 라고 합니다. 이 글에서는 이해를 위해 Backbone Network와 BBox Network 라는 말로 풀어보겠습니다. 논문에 실린 이미지를 인용해서 이 개념을 표현해보자면 이렇습니다.
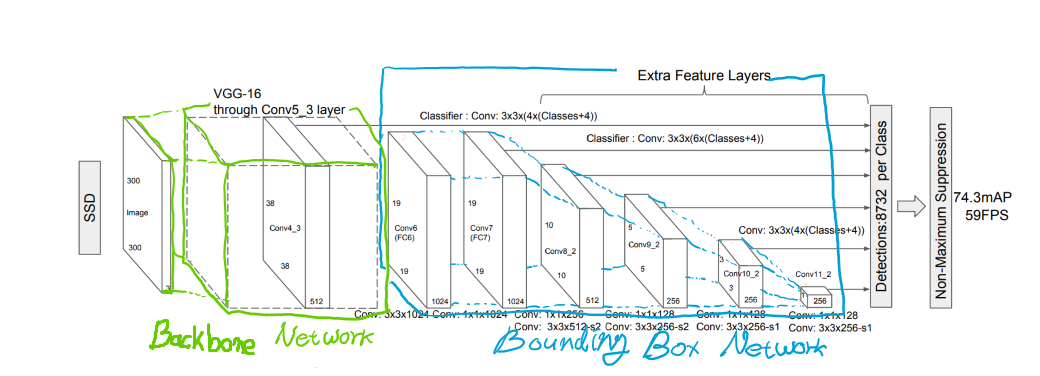
Backbone Network에서 이미지의 특징을 충분히 추출하고, BBox Network에서 여러가지 크기의 Box를 추측하는 구조로 되어있습니다. 이 말은 즉, Backbone Network는 분리될 수 있기에 어떤 신경망으로든 대체가능하며 BBox Network는 Box를 추측하는 도구로써 사용됩니다. 그렇기에 Backbone Network에서 얼마나 정밀하고 빠르게 특징을 추출하냐에 따라 SSD의 성능이 좌우된다고 할 수 있습니다.
요컨대, Backbone Network는 교체가 가능하고 그 성능에 따라 Box 추측 성능이 달라질 수 있다는 말이 됩니다.
그러므로 같은 SSD 모델이라도 Inception을 사용하는 모델과 MobileNet을 사용하는 모델의 성능과 속도 차이가 발생하는 것입니다.
SSD 모델명은 SSD_Inception_500… 또는 SSD_MobileNet_300… 등과 같이 표현합니다. SSD_Inception_500…은 입력을 500x500 사이즈로 받고 ‘SSD’를 BBox Network로 Wrapping한 Inception 모델이라는 뜻이며, SSD_MobileNet_300은 입력을 300x300 사이즈로 받고 ‘SSD’를 BBox Network로 Wrapping한 MobileNet 모델이라는 뜻입니다. YOLO_Inception도 같은 맥락으로 Inception을 ‘YOLO’라는 BBox Network로 Wrapping 했다는 뜻이 됩니다.
출력 구조
한 개체당 하나의 필드로 이루어져 있다고 언급했습니다. 이 필드는 어떻게 구성되어 있는지 먼저 살펴보겠습니다.
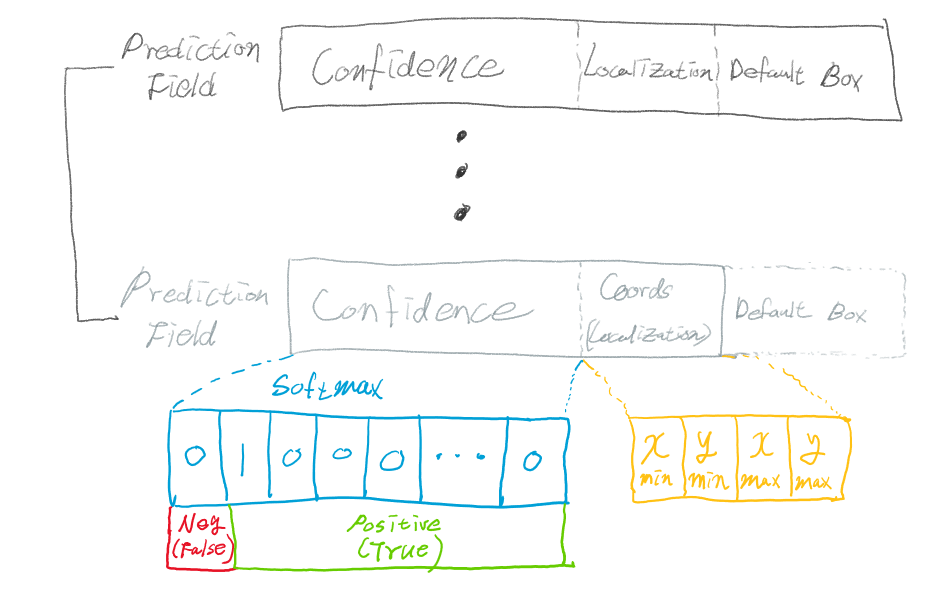
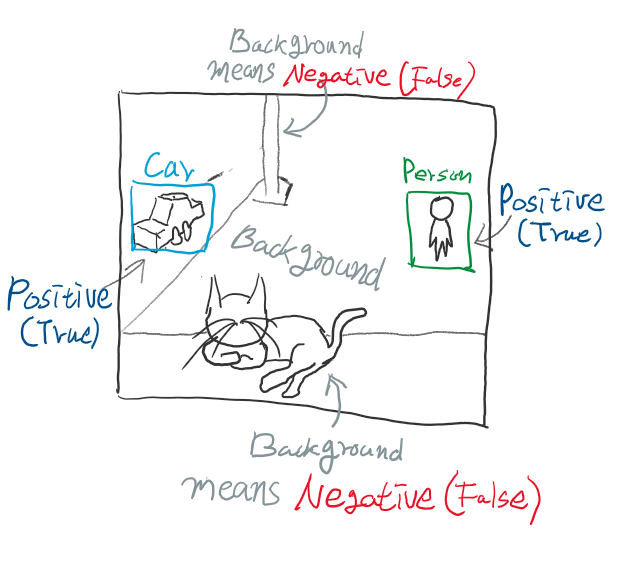
학습에 사용된 개체의 종류가 N가지라면 필드의 앞 부분은 어떤 개체인지 분류하는 Softmax 값들이 N+1개가 있고, 나머지 뒤 4개의 값은 해당 개체의 좌표라 할 수 있습니다. 여기서 분류 값이 N+1개인 이유는 학습에 사용되지 못한 개체를 Negative(False)로 표현하기 위해 맨 앞 값을 ‘background’라는 이름으로 추가했기 때문입니다.
예를 들자면, 자동차와 사람을 학습시키려 하는데 강아지나 고양이가 이미지에 포함돼있다면 0번 인덱스인 ‘background’로 분류시켜 Negative(False)임을 명시하는 것입니다.
SSD 논문에서 사용된 SSD_VGG16 모델 기준으로 앞서 언급된 필드가 8,732개가 생성됩니다. 여기까지는 YOLO와 크게 다른점은 없습니다. SSD는 추가로 아이디어를 적용해 개체의 크기별 인식율을 개선했습니다.
먼저, Backbone_Network에서 가장 날 것(Raw)에 가까운 특징들을 가지고 5,776개의 필드를 생성합니다. 그 다음 FC7 레이어에서 특징을 더 조합하여 2,166개의 필드를 생성하고, Conv8_2 레이어에서 더 조합된 특징으로 600개의 필드를 생성합니다. 이 과정을 반복해 BBox Network의 레이어를 거칠수록 점점 넓은 픽셀에서 깊은 특징을 파악하여 박스를 예측할 수 있게 됩니다.